2 min read
0
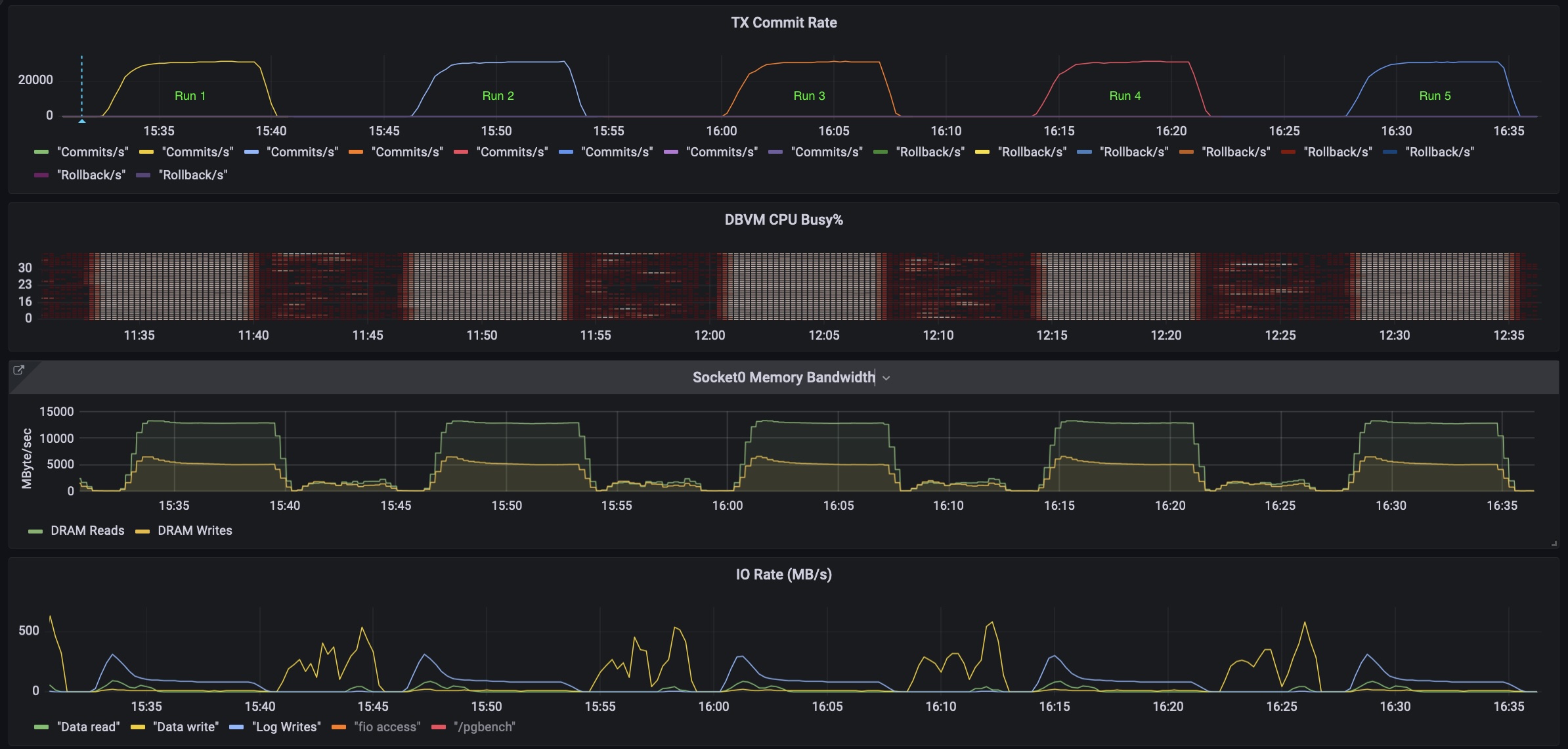
Notes on tuning postgres for cpu and memory benchmarking
Recently I wanted to measure the impact of NUMA placement and Hugepages on the performance of postgres running in a…
Testing and Benchmarking PostgresDB