Previously we looked at how the POSIX_FADVISE_DONTNEED hint influences the Linux page cache when doing IO via a filesystem. Here we take a look at two more filesystem hints POSIX_FADV_RANDOM and POSIX_FADV_SEQUENTIAL

Test setup
I created a 1GB file using dd, written out to an ext2 filesystem, then ran a simple C program against it that sequentially reads through the file with an 8KB blocksize.
while ((read(fd, buffer, sizeof(buffer) )) > 0) {
printf("");The hints are given to the filesystem by passing the file descriptor in question, a range of blocks (or the entire file) and the hint. In the example below we (incorrectly) hint at random access for the file “testfile” across the entire range.
fd=open("testfile",O_RDONLY);
posix_fadvise(fd,0,0,POSIX_FADV_RANDOM);Before running the test I clear the Linux filesystem cache so that we force the filesystem to fetch IO from disk, using the following command as root echo 3 > /proc/sys/vm/drop_caches
Results
The impact of giving the wrong hint is massive – more than 15X worse than either giving the correct hint, or not hinting at all. Not hinting gives about the same performance as the correct hint, so we can say (for this case) that the filesystem is making a good guess about the workload.
- Time to read 1GB using
POSIX_FADV_RANDOM= 16 seconds - Time to read 1GB using
POSIX_FADV_SEQUENTIAL= 0.7s
(So why hint at all if the filesystem gets it right? We may not want to rely on the filesystem guessing our access patterns and other filesystems may not be as good at guessing)
What is happening underneath?
Using POSIX_FADV_SEQUENTIAL causes the ext2/4 filesystem to read-ahead asynchronously and with a larger IO size than the user process actually asks for, whereas POSIX_FADV_RANDOM does neither (similar behavior/speed was observed for ext2 and ext4 filesystems)
How do we know this?
We know that the user process (our C program) is issuing 8KB reads sequentially (to the filesystem).
We can then look “underneath” the filesystem at the SCSI devices and inspect the IO stream issued to the disks. If the IO issued to the disks is different than the IO issued to the filesystem (by our program) then the difference must be caused by the filesystem itself and influenced by the hints.
I used two tools to inspect the IO stream to the disks, iostat and blktrace
IOSTAT view
iostat output when using POSIX_FADV_RANDOM
The iosize in iostat matched the 8k request size (areq-sz) and IO is also (probably) synchronous (aqu-sz <1). The iorate is 70MB/s – and at that rate it will take 15s to read 1GB which is what we see.

iostat output when using POSIX_FADV_SEQUENTIAL
The iosize is much larger (areq-sz ~800KB > 8KB) and the io is also asynchronous (aqu-sz >1). The filesystem is probably asking for 1MB IO’s but we do not see whole 1MB IO’s for a variety of reasons… due to driver limitations and physical page-fragmentation. The larger IO sizes and increased concurrency (via asynchronous IO requests) gives us nearly 1.5GB/s on the exact same device (compared to 70MB/s doing 8KB synchronously).

blktrace view
Using blktrace we can see the individual IO’s issued to the disk – so we can confirm the individual IO sizes and whether the IOs are synchronous or not.
bloktrace output with POSIX_FADV_RANDOM
blktrace shows that the SCSI device asks for 16 blocks of 512 bytes which is the same as the 8KB that the application asks for. The requests and completions never overlap so we can say that the IO requests are also synchronous.

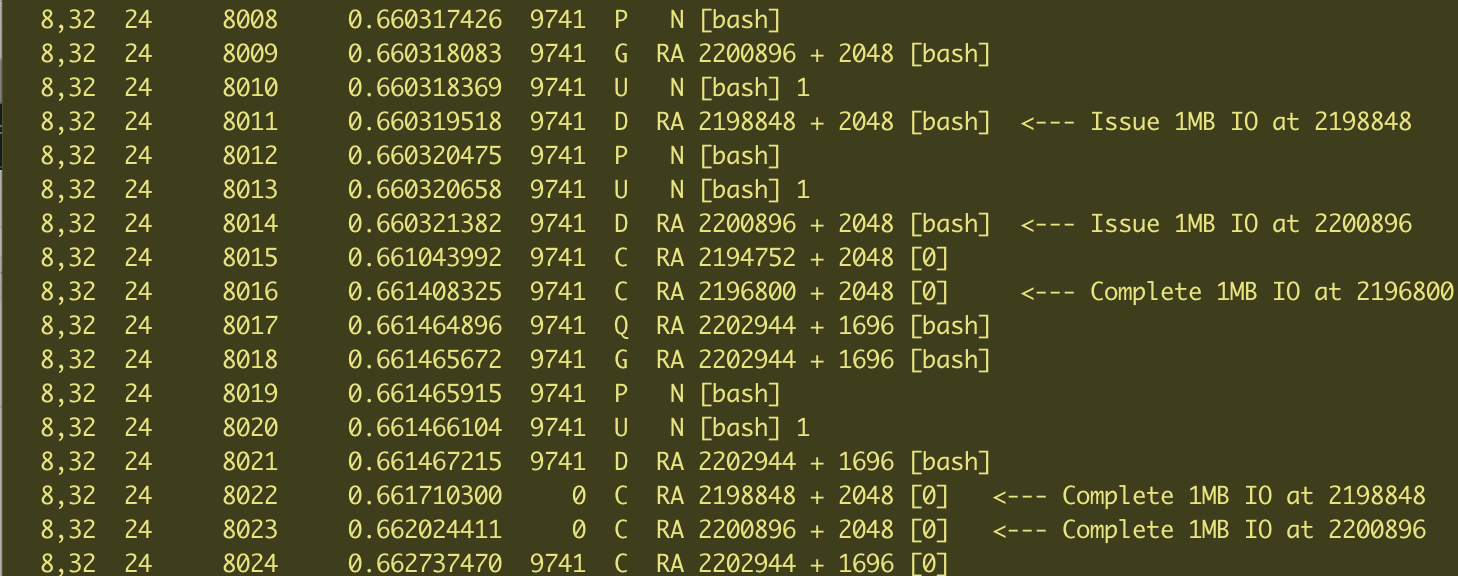
blktrace output with POSIX_FADV_SEQUENTIAL
When we switch to using the sequential hint, the SCSI device issues Much larger IO sizes (800K to 1MB) We also see that the requests and completions overlap so the IO is being issued to disk asynchronously.
Conclusion
The filesystem here is doing a great job of improving the performance of our “application” – translating synchronous 8KB reads into 1MB(ish) asynchronous reads to the underlying storage. Just make sure that if you choose to use filesystem hints that you understand what’s happening underneath.
Code
Here is the code to generate the workload.
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <fcntl.h>
int main() {
int fd;
fd=open("testfile",O_RDONLY);
posix_fadvise(fd,0,0,POSIX_FADV_RANDOM);
char buffer[8192];
/* Read the file sequentially */
while ((read(fd, buffer, sizeof(buffer) )) > 0) {
printf("");
}
}