Some technical notes on our submission to the benchmark committee.
Background
For the past few months engineers from Nutanix have been participating in the MLPerftm Storage benchmark which is designed to measure the storage performance required for ML training workloads.
We are pleased with how well our general-purpose file-server has delivered against the demands of this high throughput workload.
Benchmark throughput and dataset
- 125,000 files
- 16.7 TB of data around 30% of the usable capacity (no “short stroking”)
- Filesize 57-213MB per file
- NFS v4 over Ethernet
- 5GB/s delivered per compute node from single NFSv4 mountpoint
- 25GB/s delivered across 5 compute nodes from single NFSv4 mountpoint
The dataset was 125,000 files consuming 16.7 TB, the file sizes ranged from 57 MB to 213 MB. There is no temporal or spatial hotspot (meaning that the entire dataset is read) so there is no opportunity to cache the data in DRAM – the data is being accessed from NVMe flash media. For our benchmark submission we used standard NFSv4, standard Ethernet using the same Nutanix file-serving software that already powers everything from VDI users home-directories, medical images and more. No infiniband or special purpose parallel filesystems were harmed in this benchmark submission.
Benchmark Metric
The benchmark metric is the number of accelerators that the storage can keep busy. In the first ML-Perf benchmark report we showed that we were able to supply enough storage bandwidth to drive 65 datacenter class ML processors (called “accelerators” in MLPerftm language) with a modest 5-node Nutanix cluster. We believe that 65 accelerators maps to about 8x NVIDIA DGX-1 boxes. The delivered throughput was 5 GBytes per second over a single NFS mountpoint to a single client, or 25GB/s to 5 clients using the same single mountpoint. Enforcing that the results are delivered over a single NFS mountpoint helps to avoid simplistic hard-partitioning of the benchmark data.
Benchmark Setup
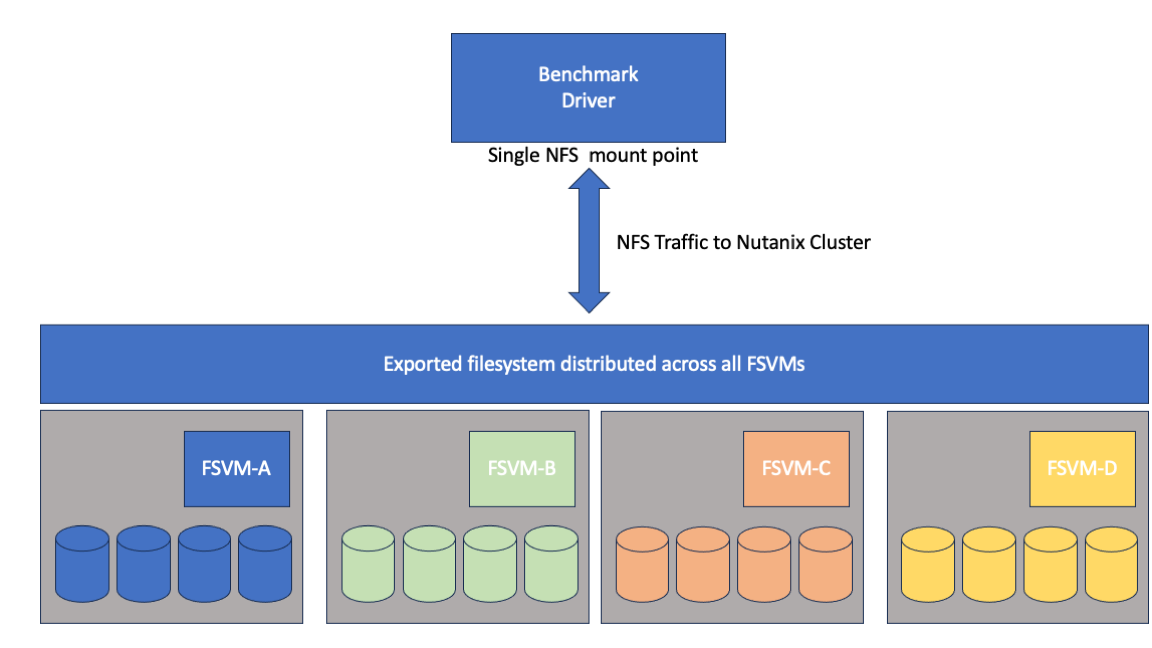
How is it possible to provide such high throughput over a large dataset using standard HCI nodes and standard NFS file services? The short answer is by distributing both data and load equally across the entire cluster. Nutanix Files implements a cluster of virtual file-servers (FSVMS) to act as a distributed NAS storage head. We place these FSVMs on our existing VM storage which acts as a distributed virtual disk-shelf providing storage to the FSVMs.
The result is a high performance filer where storage compute load and data is spread across physical nodes and the disks within the nodes – thus avoiding hotspots.
- Each CVM uses all the local disks in the host for data, metadata and write log
- Each FSVM uses all CVMs to load balance its back-end
- Each NFS mount is balanced across all FSVMs using NFS V4 referrals (no client configuration required)
- On the linux client we use the mount option nconnect=16 to generate multiple TCP streams per mountpoint
A Single File-Server VM (virtual storage controller) spreads its data disks (virtual disk shelf) across all nodes in the cluster

We repeat for each File-Server VM in the cluster

This cluster of file-server VMs act as a single virtual storage controller. In the case of the benchmark the work is performed over a single mount point. Beneath this mountpoint the workload is spread across all of the FSVM’s using NFSv4 referrals. No client-side configuration is required.

To improve network throughput, we use the Linux mount option nconnect=16 which gives 16 TCP/IP streams per mountpoint.
Our NFS solution is based on top of the Nutanix storage layer that we have been fine-tuning for over 10 years to provide high performance storage to VMs. The secret sauce of our performance can be summarized as “distributed everything”.
- All nodes in the cluster contribute to storage performance
- All nodes contribute to metadata performance – there is no idea of a “metadata server” subset of nodes. All nodes contribute to both data and metadata performance
- All physical disks in the system contribute to capacity and performance.
- Data placement and optimization decisions are made in real time based on the incoming IO stream – data can be placed anywhere in the cluster at any time since all operations are distributed.
Taken together, all of this means we can put data in the right place at the right time in realtime.
We take the same philosophy and apply it to the filer server layer. Our File Server is implemented as a set of file-server VMs (FSVMs) that operate together to provide a single namespace. The number of FSVMs depends on the number of nodes in the Nutanix cluster.
To avoid hotspots each FSVM creates its “back-end” using disks across multiple nodes. It sounds complex, but is all handled behind the scenes using NFS v4 referrals (RFC 7530)
The ML-Perf Storage benchmark is strictly focused on storage performance and we decided to pursue the unet3D workload which is an image based ML workload since it has the highest storage performance requirements. Real-world applications for unet3D could be any type image recognition from surveillance to retail checkouts.
ML Inferencing on hyper-converged infrastructure is already popular, because of the robust nature of the platform which is critical at the near-edge. What is less usual is performing training on HCI due to the high throughput requirements. Until now training has been thought of as requiring specialist storage appliances, however our experience with the benchmark has shown that our general purpose hyper-converged file-server can provide substantial throughput performance.