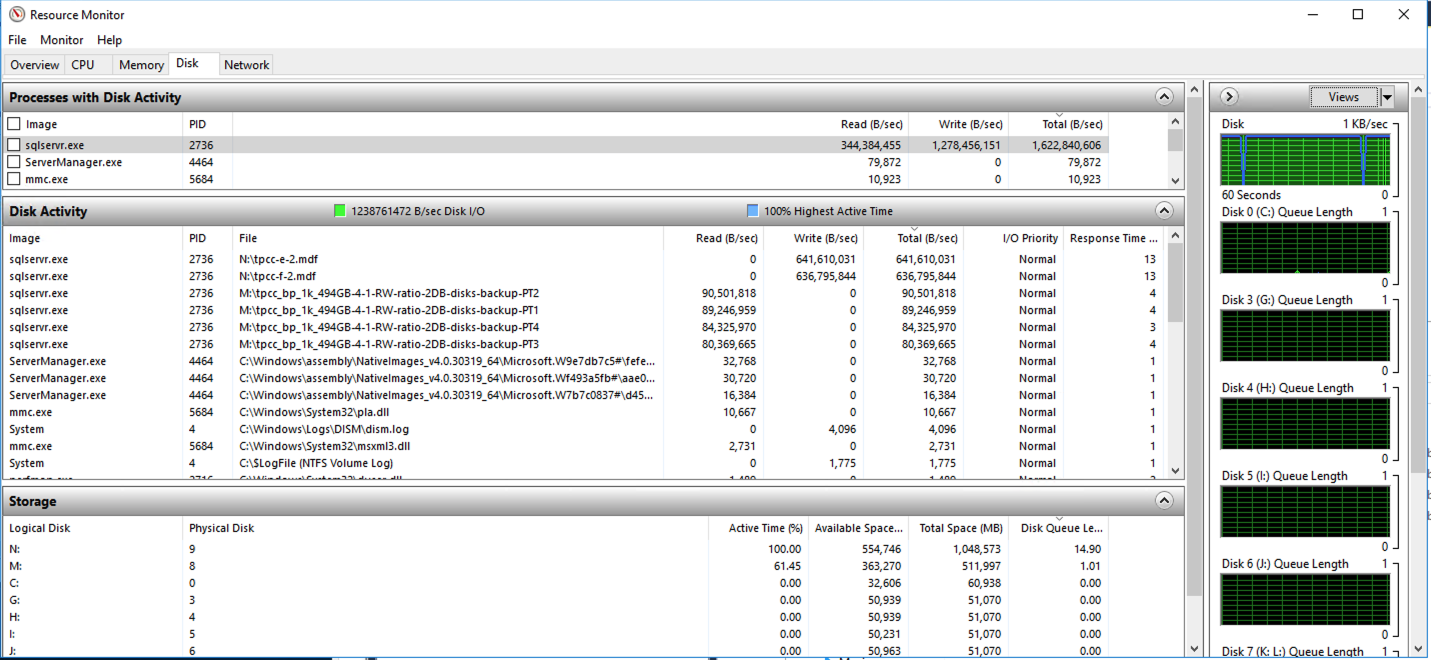
1 min read 0 Nutanix AOS 6.1 Improvements for Day-2 database operations. gary March 8, 2022 AOS 6.1 greatly improved database performance on Nutanix especially when the guest VM uses just a single disk for all…
2 min read 0 Nutanix Nutanix AES: Performance By Example PT2 gary December 18, 2018 How to improve large DB read performance by 2X Nutanix AOS 5.10 ships with a feature called Autonomous Extent Store…
2 min read 0 Nutanix Nutanix AES: Performance By Example. gary December 17, 2018 How to reduce database restore time by 50% During .Next 2018 in London, Nutanix announced performance improvements in the core-datapath…