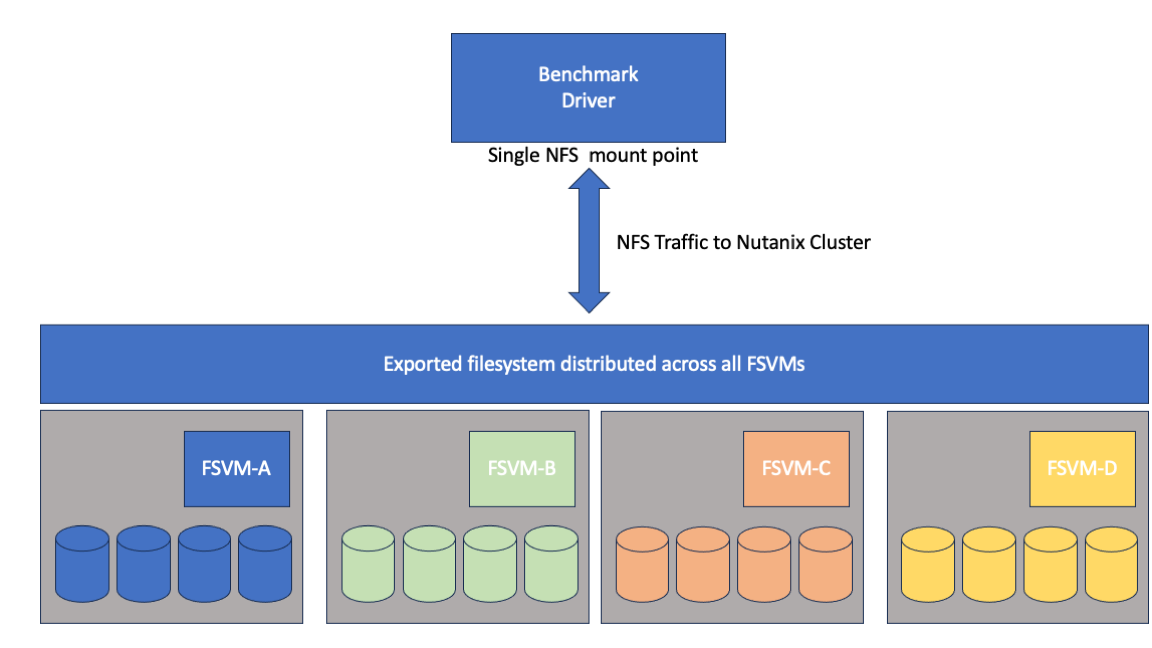
1 min read 0 Workloads & Benchmarks Running the ML-Perf Storage benchmark on Nutanix files. gary September 15, 2023 Some technical notes on our submission to the benchmark committee. Background For the past few months engineers from Nutanix have…